Nächstes Level für Simulationen in der Produktentwicklung dank KI
Um die Produktentwicklung zu beschleunigen und trotzdem günstig und zuverlässig zu halten, verwenden Ingenieure anstelle von Prototypen, wenn möglich physikalische Simulationen. Dabei stützen sie sich auf physikalische Gesetze, die in Form von partiellen Differentialgleichungen formuliert werden und deren Lösung standardmässig mit etablierten numerischen Techniken berechnet wird. Ein neuer Trend nutzt Elemente der künstlichen Intelligenz, um einige Einschränkungen der Standardmethoden zu überwinden und die Simulationen in der Produktentwicklung auf das nächste Level zu bringen.

(Bild: ThisisEngineering RAEng – Unsplash)
In diesem Artikel soll ein Überblick über den aktuellen Stand der Technik dieses Ansatzes gegeben werden. Ausserdem wird das Potenzial im Hinblick auf praktische Anwendungen in der industriellen Hardware-Produktentwicklung erörtert.
1. Einleitung: Schnelle, zuverlässige und günstige Produktentwicklung dank Simulationen
In der modernen Produktentwicklung spielen Entwicklungszeit, Zuverlässigkeit und Kosten eine zentrale Rolle für den wirtschaftlichen Erfolg eines Produktes. Zu hohe Entwicklungskosten, die mit dem Verkaufspreis amortisiert werden müssen, können zu einem kompetitiven Nachteil führen. Dauert die Entwicklung zu lang, werden Chancen verpasst, möglicherweise zugunsten der Konkurrenz. Falls die Entwicklung unvollständig durchgeführt wurde, ergeben sich Fehler im Feld, die die Marktpenetration und das Ansehen des Herstellers negativ beeinflussen und zu rechtlichen Konsequenzen führen können.
In der Hardwareentwicklung ist es unabdingbar, einige Iterationen des zu entwickelnden Produktes mit entsprechenden Prototypen zu testen. Je nach Produktart und Marktsegment kann das drei bis Dutzende solcher Iterationen bedeuten, was sowohl zu Zeit-, Personal- als auch Materialkosten führt. Um die Anzahl solcher Schritte zu minimieren, setzen Ingenieure standardmässig Computerprogramme ein, die die spezifischen Eigenschaften des zu prüfenden Prototyps auf der Grundlage seines Designs vorhersagen können. Dabei werden die verschiedenen Teile des Systems inklusive deren Materialeigenschaften betrachtet und im Zusammenhang mit den entsprechenden physikalischen Gesetzen numerisch berechnet. Somit kann mit einer gewissen Toleranz im Vorfeld berechnet werden, ob zum Beispiel eine Baustruktur stabil ist oder ob ein Mikroprozessor in Betrieb nicht zu heiss wird. Da die Grundlagen dafür die entsprechenden Gesetze der Physik sind, kann dieser Ansatz auf eine enorme Anzahl von Produktarten und Fragestellungen angewendet werden: von der Optimierung des aerodynamischen Profils eines Flugzeugflügels durch die Maximierung der Emission einer Antenne bis hin zur Bestimmung der Deformation eines Fahrzeugs bei einer Kollision.
2. Physik, Mathematik und Numerik zur Rettung der Produktentwicklung
Trotz der riesigen Vielfalt an Situationen, die mit solchen Simulationen modelliert werden können, gibt es einen gemeinsamen Nenner: Die Situationen basieren alle auf einer spezifischen Art von mathematischen Zusammenhängen, die sehr häufig in der Physik vorkommen: die sogenannten partiellen Differentialgleichungen. Diese sind durch die Tatsache charakterisiert, dass sie nicht eine direkte Beziehung zwischen einzelnen physikalischen Zahlen bestimmen, sondern auf einem Zusammenhang zwischen den Verläufen von Messgrössen basieren. Um den Unterschied zu erläutern, können hier zwei einfache Beispiele benutzt werden. Bei einer konventionellen Gleichung bekommt man eine unbekannte Zahl, berechnet aus den bekannten Werten, wie etwa bei der Bestimmung der Fläche einer Tischplatte aus der Messung der Länge und der Breite. Eine Differentialgleichung bestimmt hingegen, wie die Variation einer Grösse in Zusammenhang mit sich selbst und anderen Grössen steht. Zum Beispiel hängt die Bremskraft eines auf der Autobahn fahrenden Personenwagens von dessen Geschwindigkeit ab. Diese Kraft bestimmt auch die Beschleunigung des Fahrzeuges, das heisst, wie seine Geschwindigkeit sich mit der Zeit ändert. Diese komplexe Beziehung kann mathematisch aufgestellt werden, aber das bedingt, dass man nicht einfach einen einzigen Wert der Geschwindigkeit findet, sondern ihren gesamten Verlauf in Abhängigkeit der Zeit bestimmt. Das heisst, man sucht letztlich die Geschwindigkeit als eine Funktion der Zeit und nicht als einen Einzelwert.
Partielle Differentialgleichungen stellen ein sehr mächtiges Rechenwerkzeug dar, denn sie kommen bei vielen physikalischen Phänomenen zum Einsatz. Zu dieser Klasse der Gleichungen gehören beispielsweise die Gesetze des Elektromagnetismus, der Wellenausbreitung, der Wärmeverteilung, der Fluiddynamik, der Elastostatik, der Dynamik und der Quantenmechanik. Die grösste Herausforderung dabei ist, dass sie auch komplexe mathematische Probleme darstellen, die ausser in sehr trivialen und nicht praxisrelevanten Situationen keine explizite Lösung mit Bleistift und Papier ermöglichen. Dazu sind computergestützte Berechnungen nötig, mithilfe derer die jeweiligen Differentialgleichungen numerisch gelöst werden. Es gibt dafür verschiedene Techniken, die aber fast ohne Ausnahmen auf einem ähnlichen Prinzip beruhen, nämlich auf der Annäherung der stetigen Veränderung der gesuchten Grösse mit kleinen, aber finiten Differenzen. Ein Beispiel dafür ist, wenn man die Position eines Fahrzeugs an zwei Augenblicken, die nur eine Zehntelsekunde auseinander sind, bestimmt, um die Geschwindigkeit als Strecke durch Zeit zu schätzen. Dieser Schritt wird zwar nötig, denn stetige Änderungen lassen sich auf einem digitalen System nicht trivial abbilden. Zu diesem Zweck müssen die meisten solcher Methoden das elektronisch hinterlegte Design des Prototyps in viele kleine vernetzte Elementen zerlegen, damit die Annäherung mit finiten Differenzen das Schlussresultat möglichst wenig beeinträchtigt.
In der Lösung von partiellen Differentialgleichungen zur Modellierung von Hardwaredesigns sind finite Annäherungen seit mehreren Dekaden Industriestandard. Der Umgang mit den verschiedenen professionellen Softwarepaketen, die dies ermöglichen, gehört zu jedem typischen Ausbildungsprogramm für Ingenieure sowie zum Alltag von jeder Hardwareentwicklungsabteilung.
Dank dieser etablierten und langjährigen Erfahrung sind neben dem grossen Potenzial auch die Einschränkungen von diesen Techniken bekannt. Da die Lösung sich auf kleine Elemente stützt, ist es nicht immer möglich, diese noch weiter zu zerlegen, sodass die räumliche Auf lösung intrinsisch eingeschränkt ist. Wenn man eine feinere Antwort braucht, muss die Zerlegung in Elemente neu gemacht werden. Das ist umso mehr der Fall, wenn eine Reihe von Simulationen mit variierender Geometrie durchgeführt wird, etwa wie bei der Optimierung der Form oder der Grössen einer Struktur: In solchen Situationen muss die Zerlegung in Elemente immer wieder aktualisiert werden, was rechnerisch aufwendig ist und den Vergleich zwischen den verschiedenen Simulationen erschwert. Ferner benötigen Problemstellungen mit vielen freien Parametern, wie zum Beispiel der zeitliche Verlauf der Temperatur über einer dreidimensionalen Struktur, extrem viele Rechenressourcen, sodass sie manchmal praktisch nicht durchführbar sind. Weitere Schwierigkeiten dieser Techniken ergeben sich bei komplexen Zusam menhängen zwischen den untersuchten Grössen, die entstehen, wenn der gekoppelte Effekt von mehreren physikalischen Prinzipien gleichzeitig untersucht wird (die sogenannte Multi-Physik). Ein Beispiel dafür ist, wenn die mechanischen Deformationen einer Struktur als Konsequenz von Erwärmung untersucht werden, indem ein Problem der Elastostatik und eines der Wärmelehre in einer gekoppelten Simulation gleichzeitig analysiert werden.
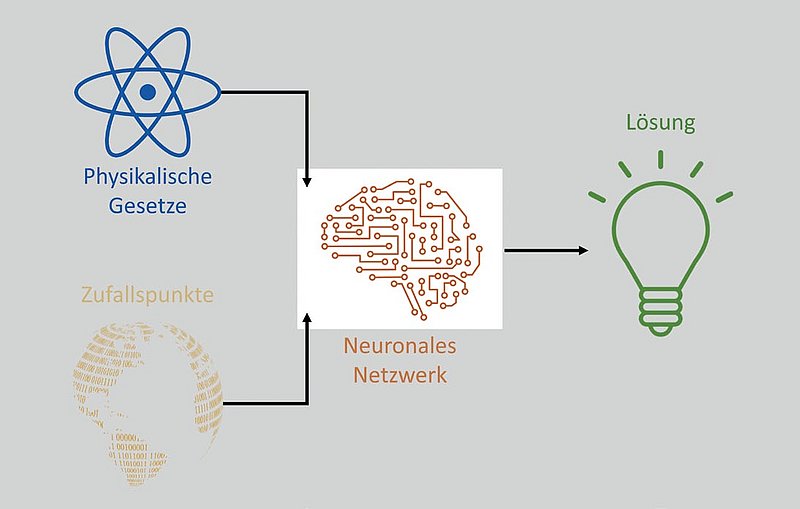
Die Elemente künstlicher Intelligenz, um die Simulationen in der Produktentwicklung auf das nächste Level zu bringen.
3. Eine mögliche Revolution: Partielle Differentialgleichungen mit künstlicher Intelligenz
Ein alternatives Paradigma zur Lösung von partiellen Differentialgleichungen wurde in den 1990ern vorgeschlagen und in den letzten Jahren wieder belebt. Dieser Ansatz basiert auf der Verwendung eines Werkzeugs der künstlichen Intelligenz: den neuronalen Netzwerken. Diese basieren auf kleinen Einheiten (Neuronen). Die Neuronen verarbeiten die Eingangssignale in Abhängigkeit von justierbaren Parametern und werden miteinander in einem Netz verbunden, um eine quantitative Verarbeitung von Eingängen in passenden Ausgängen als Funktion von passenden Parametern zu ermöglichen. Die Komplexität dieser Verarbeitung erfolgt aufbauend mittels mehrerer Schichten von solchen Neuronen. Diese Struktur führt dazu, dass solche Netze eine Beziehung zwischen Eingängen und Ausgängen aus einem Datensatz «lernen» können. Das heisst, sie können anhand einer passenden Stichprobe von Beispielwerten am Ein- und Ausgang eine Funktion lernen. Zudem kann man bei neuronalen Netzwerken stetige Differenzen exakt berechnen, ohne auf finite Differenzen ausweichen zu müssen. Diese Eigenschaften charakterisieren neuronale Netzwerke als perfekte Kandidaten, um die Lösung von einer gewissen Differentialgleichung zu lernen, indem sie so trainiert werden, dass die Bedingung, die durch die Differenzialgleichung bestimmt ist, bei ausgewählten Eingangswerten möglichst gut erfüllt wird. Dank des systematischen Einsatzes von neuronalen Netzwerken im ständig wachsenden Bereich von Data Science gibt es heutzutage viele benutzerfreundliche dedizierte Bibliotheken, die ein Wiederbeleben von diesem Ansatz zur Lösung von Differentialgleichungen gefördert hat.
Der Motivationsfaktor dieses Forschungsbereichs liegt darin, dass der untersuchte Ansatz einige potenzielle Vorteile gegenüber den oben beschriebenen traditionellen Techniken bietet. Zum einen entfällt dabei der Bedarf einer Annäherung für die Differenzen. Somit ist keine Zerlegung in Elemente mehr nötig, sondern es reicht, wenn man einzelne repräsentative Stützpunkte aus dem zu un tersuchenden Design klug auswählt. Dieses überwindet automatisch alle oben erwähnten Nachteile, die in Zusammenhang mit der Zerlegung stehen. Somit werden die Optimierung von variierenden Geometrien sowie der Vergleich zwischen den verschiedenen Iterationen der Simulation nicht beeinträchtigt. Man kann im Prinzip sogar die zu optimierenden Parameter als kontinuierliche Variablen in der Problemstellung anstelle von diskretisierten Schritten einbauen. Die Lösungen, die man mit neuronalen Netzwerken bekommt, lassen sich zudem gut ausserhalb der Stützpunkte generalisieren, das heisst, sie sind auch bei anderen Punkten zuverlässig. Ein weiterer Vorteil dieses Ansatzes ist, dass der entspre chende rechnerische Aufwand, im Gegensatz zu den traditionellen Techniken, nicht stark von der Anzahl Eingangsparameter sowie von der Komplexität der physikalischen Zusammenhänge abhängt. Dies bedeutet, dass die Lösung von partiellen Differentialgleichungen mittels neuronaler Netzwerke das Potenzial hat, Simulationsprobleme zu lösen, die mit konventionellen Techniken sehr schwierig bis gar unmöglich sind. Diese Technik kann zusätzlich von der ständigen und schnellen Entwicklung der künstlichen Intelligenz in verschiedenen wachsenden Bereichen wie der Bilderkennung oder Sprachverarbeitung profitieren. Damit wird die rechnerische Effizienz und Reichweite bezüglich der adressierbaren Problemstellungen auch im Bereich der physikalischen Simulationen gestärkt. Im Vergleich zu den typischen Problemstellungen der Data Science profitiert dieses Forschungsfeld von der luxuriösen Situation, dass die Daten für das Training nicht gemessen oder erworben werden müssen, sondern nach Bedarf generiert werden können. Zudem sind sie im Gegensatz zu herkömmlichen Daten völlig frei von Rauschen, denn sie entstehen aus einer exakten mathematischen Beziehung, nämlich diejenigen, die von der Differentialgleichung definiert wird.
Trotz dieser potenziellen Vorteile wurde die Lösung von Differentialgleichungen mit neuronalen Netzwerken bis jetzt noch nicht überzeugend und systematisch mit den traditionellen Methoden verglichen. Es konnte auch noch nicht bewiesen werden, dass das Potenzial tatsächlich genutzt werden kann. Die wenigen bisherigen Studien in diese Richtung beleuchten diesen Vergleich nur partiell und schränken sich meistens auf sehr einfache Situationen ohne grosse Praxisrelevanz ein. Der Literatur fehlt also momentan eine systematische Analyse der tatsächlichen Vorteile, insbesondere im Rahmen von praktischen industriellen Anwendungen. Ein Grund dafür ist natürlich die Neuigkeit der Technik, die dazu führt, dass es anders als bei Standardtechniken noch keine dedizierten Softwarepakete gibt. Es gibt zwar einige Frame- works dazu, aber diese sind weder reif noch professionell aufgestellt und gelten eher als Prototypen. Alles in allem deuten die ersten Indizien, die man aus dem aktuellen Stand der Forschung eruieren kann, darauf hin, dass die versprochenen Vorteile teils tatsächlich vorhanden sind, aber wahrscheinlich noch nicht in einem revolutionären Ausmass.
4. Der Weg zur tatsächlichen Implementierung in der Praxis
Eine Kollaboration zwischen den Forschungsgruppen der zwei Autoren arbeitet gerade daran, diese Wissenslücke zu füllen. Dabei werden praxisrelevante simulationstechnische Problemstellungen aus der Industrie identifiziert und sowohl mit konventionellen Methoden als auch mit dem neuen Ansatz systematisch gelöst, sodass mit einem möglichst objektiven Vergleich die tatsächlichen Vorteile erkannt und quantifiziert werden können. Die Erkenntnisse aus der Literatur in der Grundforschung werden dabei im Blick behalten und gegebenenfalls integriert. Ein kürzlich entwickelter Ansatz verspricht zum Beispiel ein noch grösseres Potenzial: Die Möglichkeit, anstelle einzelner Differentialgleichungen ganze Klassen davon maschinell zu lernen. Die Idee dabei ist, ein Modell der künstlichen Intelligenz mit einer Menge an Lösungen von verschiedenen Differentialgleichungen derselben Art (beispielsweise alle möglichen Temperaturverteilungen auf einer rechteckigen Platine) zu trainieren, sodass diese den allgemeinen Zusammenhang lernt. Bei einer neuen Differentialgleichung vom gleichen Typ kann die KI eine ziemlich genaue Lösung quasi unverzüglich wiedergeben, die dann mit wenig Rechenaufwand verfeinert werden kann. Der Einsatz dieses Konzepts kann prinzipiell zu einer Operationskette führen, bei der das trainierte Modell als Startpunkt für jedes neue Problem der gegebenen Art verwendet wird. Jede damit resultierende neue Lösung kann in den Trainingsdaten integriert werden, womit die Genauigkeit des Modells weiter erhöht wird. Dieses System würde also von der starken Synergie zwischen seinem Datensatz und jeder neuen Anwendung davon profitieren. So erhöht jede neue Verwendung des Modells gleichzeitig seine Zuverlässigkeit. Es handelt sich also dabei um eine Software, die fast automatisch nach jeder Anwendung besser wird. Eine erfolgreiche Implementierung dieser Idee kann also theoretisch eine Revolution im Feld der physikalischen Simulationen für industrielle Anwendungen darstellen.
(Erstpublikation: polyscope, Juni 2022)
